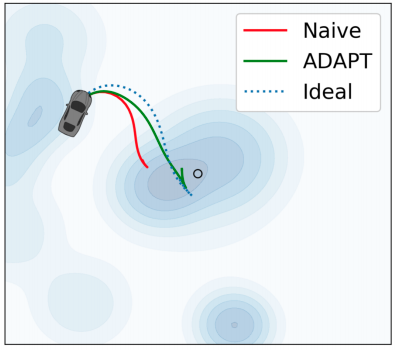
Model-free policy learning has enabled robust performance of complex tasks with relatively simple algorithms. However, this simplicity comes at the cost of requiring an Oracle and arguably very poor sample complexity. This renders such methods unsuitable for physical systems. Variants of model-based methods address this problem through the use of simulators, however, this gives rise to the problem of policy transfer from simulated to the physical system. Model mismatch due to systematic parameter shift and unmodelled dynamics error may cause sub-optimal or unsafe behavior upon direct transfer. We introduce the Adaptive Policy Transfer for Stochastic Dynamics (ADAPT) algorithm that achieves provably safe and robust, dynamically-feasible zero-shot transfer of RL-policies to new domains with dynamics error. ADAPT combines the strengths of offline policy learning in a black-box source simulator with online tube-based MPC to attenuate bounded model mismatch between the source and target dynamics. ADAPT allows online transfer of policy, trained solely in a simulation offline, to a family of unknown targets without fine-tuning. We also formally show that (i) ADAPT guarantees state and control safety through state-action tubes under the assumption of Lipschitz continuity of the divergence in dynamics and, (ii) ADAPT results in a bounded loss of reward accumulation relative to a policy trained and evaluated in the source environment. We evaluate ADAPT on 2 continuous, non-holonomic simulated dynamical systems with 4 different disturbance models, and find that ADAPT performs between 50%-300% better on mean reward accrual than direct policy transfer.