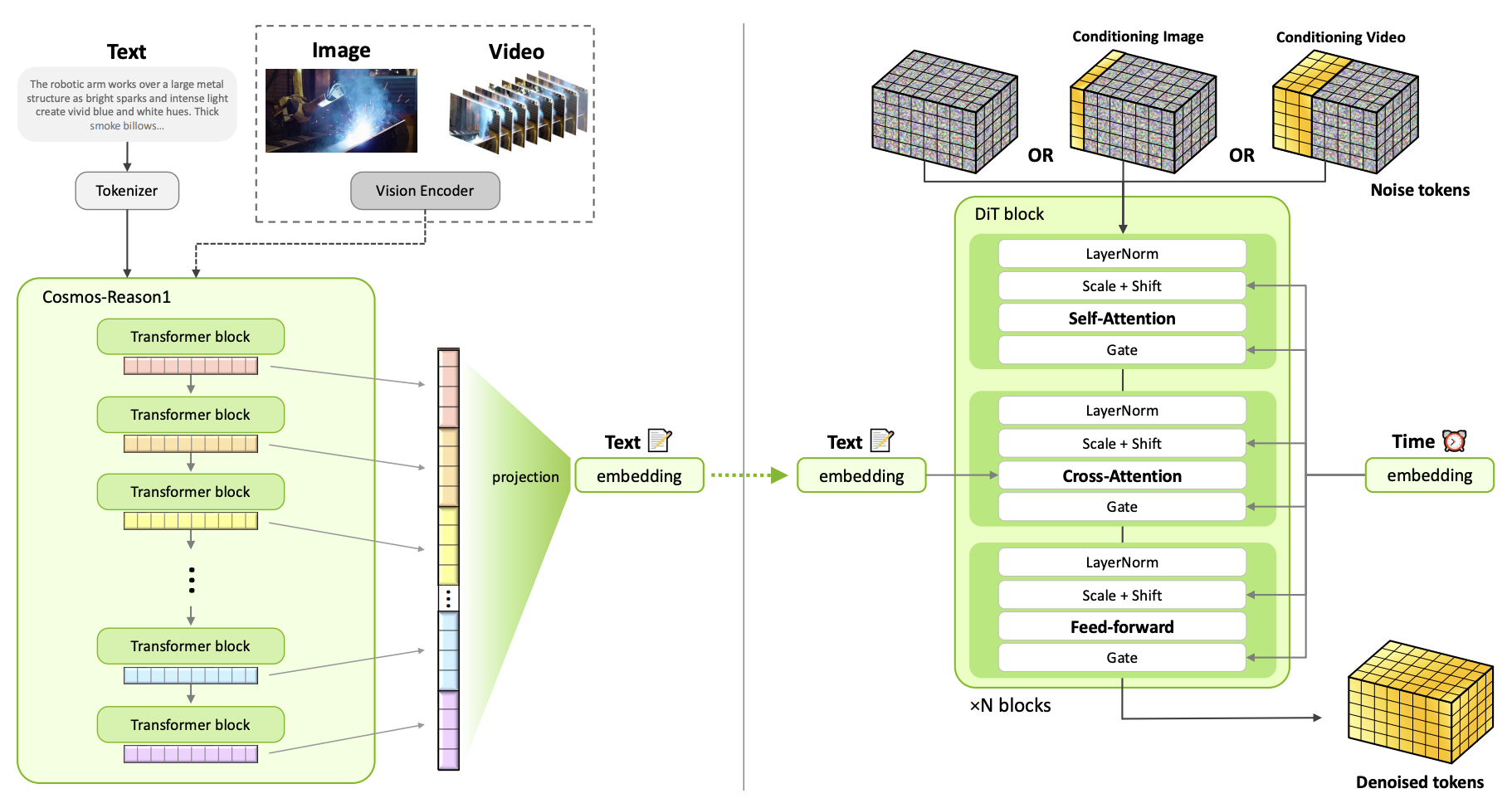
We introduce [Cosmos-Predict2.5], the latest generation of the Cosmos World Foundation Models for Physical AI. Built on a flow-based architecture, [Cosmos-Predict2.5] unifies Text2World, Image2World, and Video2World generation in a single model and leverages [Cosmos-Reason1], a Physical AI vision-language model, to provide richer text grounding and finer control of world simulation. Trained on 200M curated video clips and refined with reinforcement learning-based post-training, [Cosmos-Predict2.5] achieves substantial improvements over [Cosmos-Predict1] in video quality and instruction alignment, with models released at 2B and 14B scales. These capabilities enable more reliable synthetic data generation, policy evaluation, and closed-loop simulation for robotics and autonomous systems. We further extend the family with [Cosmos-Transfer2.5], a control-net style framework for Sim2Real and Real2Real world translation. Despite being 3.5× smaller than [Cosmos-Transfer1], it delivers higher fidelity and robust long-horizon video generation. Together, these advances establish [Cosmos-Predict2.5] and [Cosmos-Transfer2.5] as versatile tools for scaling embodied intelligence.