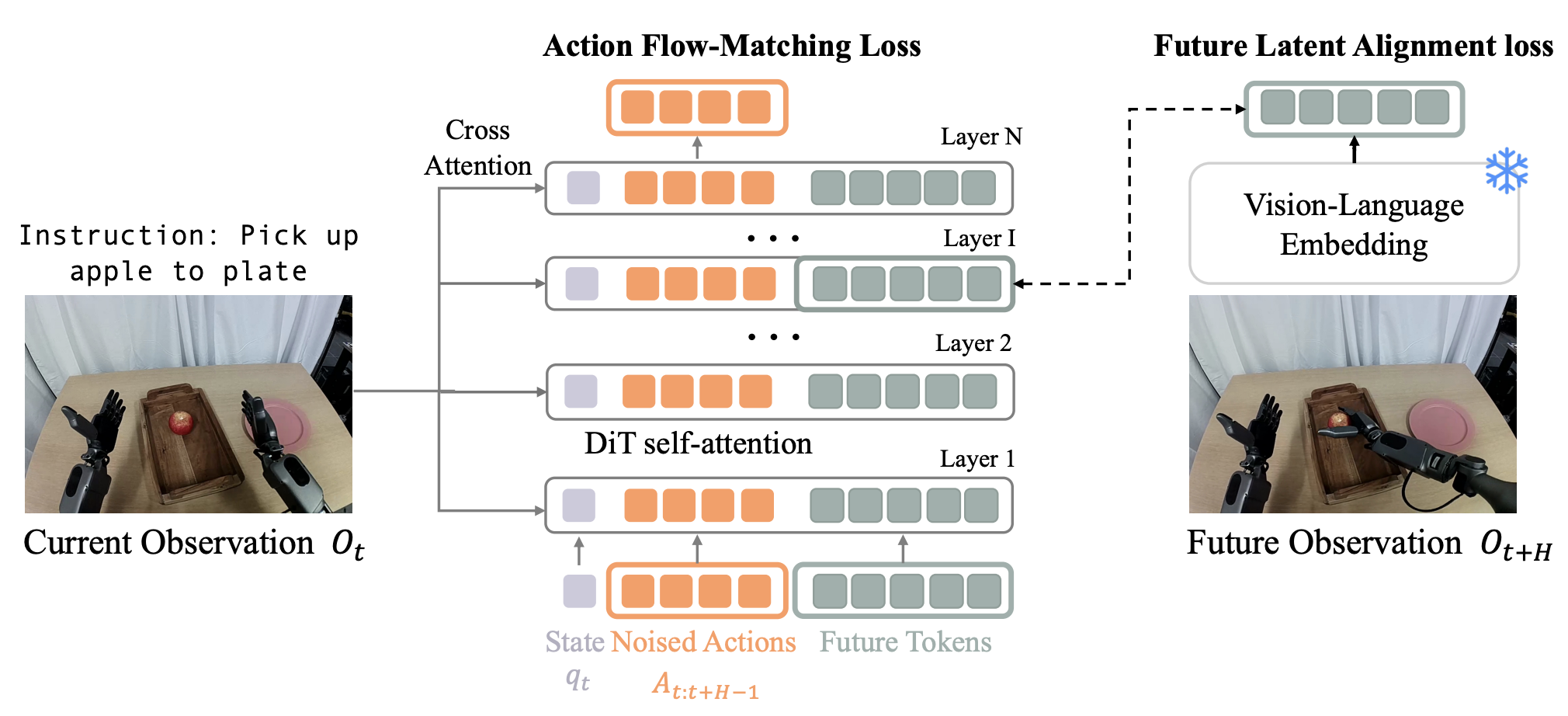
We introduce Future LAtent REpresentation Alignment (FLARE), a novel framework that integrates predictive latent world modeling into robot policy learning. By aligning features from a diffusion transformer with latent embeddings of future observations, FLARE enables a diffusion transformer policy to anticipate latent representations of future observations, allowing it to reason about long-term consequences while generating actions. Remarkably lightweight, FLARE requires only minimal architectural modifications – adding a few tokens to standard vision-language-action (VLA) models – yet delivers substantial performance gains. Across two challenging multitask simulation imitation learning benchmarks spanning single-arm and humanoid tabletop manipulation, FLARE achieves state-of-the-art performance, outperforming prior policy learning baselines by up to 26%. Moreover, FLARE unlocks the ability to co-train with human egocentric video demonstrations without action labels, significantly boosting policy generalization to a novel object with unseen geometry with as few as a single robot demonstration. Our results establish FLARE as a general and scalable approach for combining implicit world modeling with high-frequency robotic control.