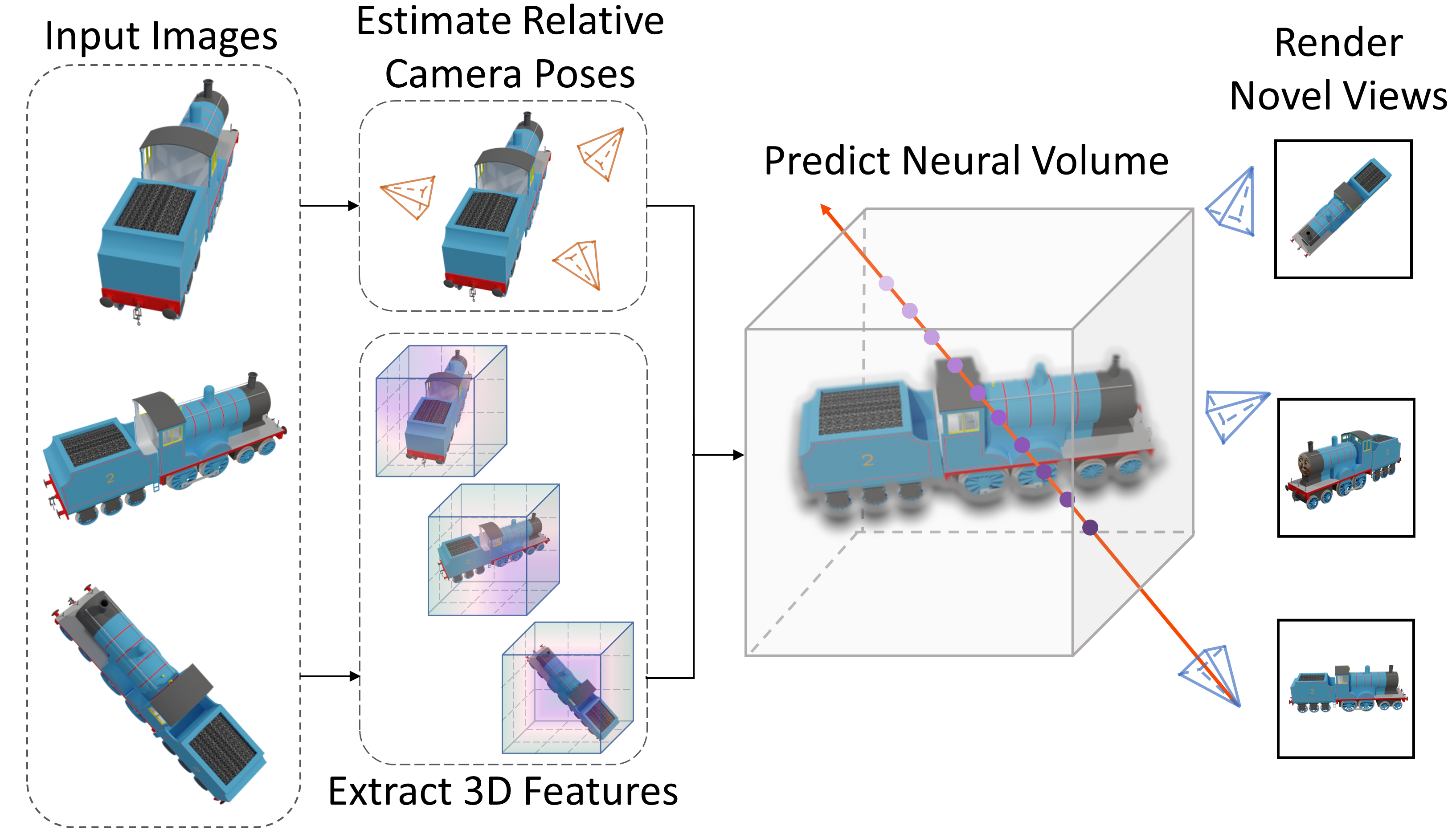
While object reconstruction has made great strides in recent years, current methods typically require densely captured images and/or known camera poses, and generalize poorly to novel object categories. To step toward object reconstruction in the wild, this work explores reconstructing general real-world objects from a few images without known camera poses or object categories. The crux of our work is solving two fundamental 3D vision problems — shape reconstruction and pose estimation — in a unified approach. Our approach captures the synergies of these two problems: reliable camera pose estimation gives rise to accurate shape reconstruction, and the accurate reconstruction, in turn, induces robust correspondence between different views and facilitates pose estimation. Our method FORGE predicts 3D features from each view and leverages them in conjunction with the input images to establish cross-view correspondence for estimating relative camera poses. The 3D features are then transformed by the estimated poses into a shared space and are fused into a neural radiance field. The reconstruction results are rendered by volume rendering techniques, enabling us to train the model without 3D shape ground-truth. Our experiments show that FORGE reliably reconstructs objects from five views. Our pose estimation method outperforms existing ones by a large margin. The reconstruction results under predicted poses are comparable to the ones using ground-truth poses. The performance on novel testing categories matches the results on categories seen during training.