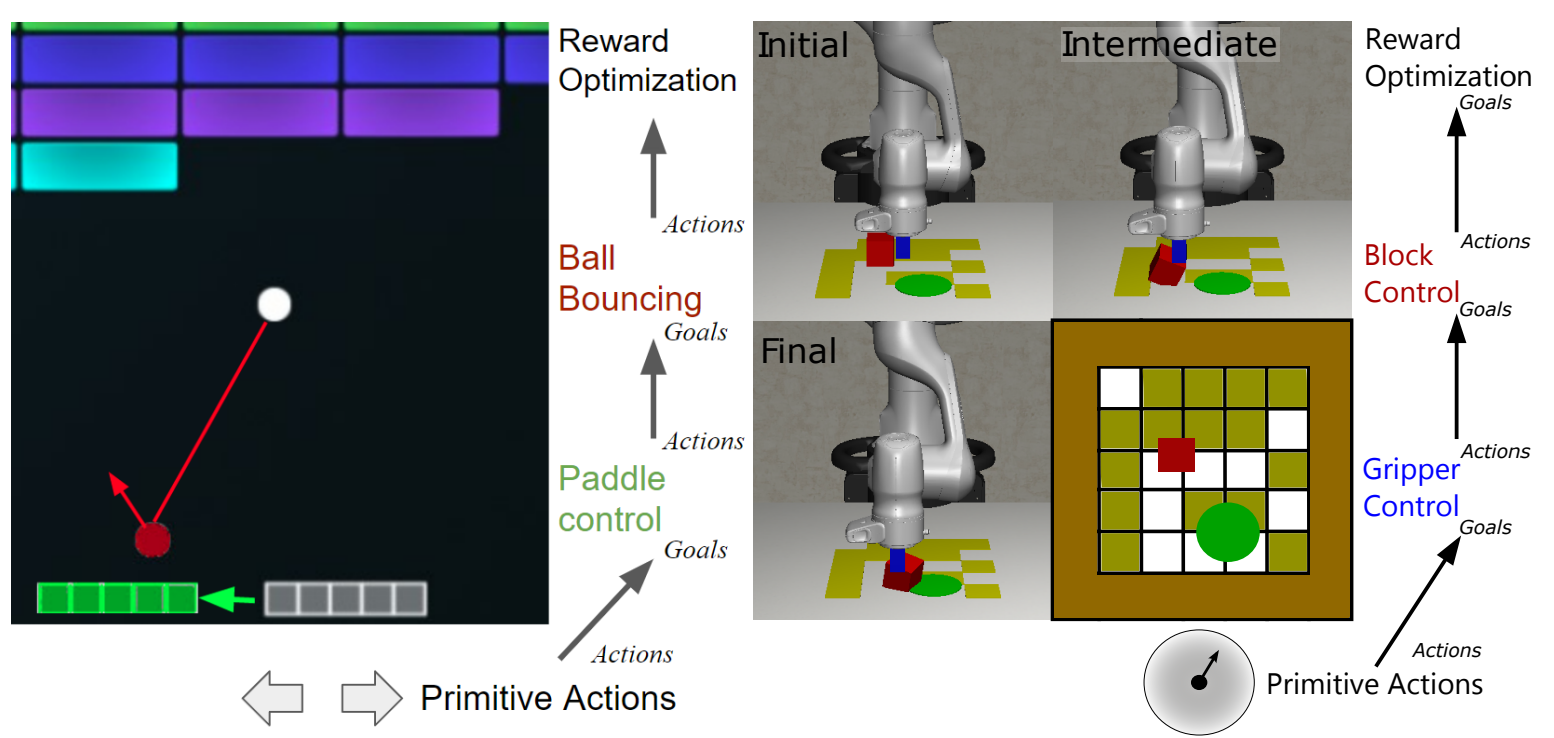
Reinforcement Learning (RL) has demonstrated promising results in learning policies for complex tasks, but it often suffers from low sample efficiency and limited transferability. Hierarchical RL (HRL) methods aim to address the difficulty of learning long-horizon tasks by decomposing policies into skills, abstracting states, and reusing skills in new tasks. However, many HRL methods require some initial task success to discover useful skills, which paradoxically may be very unlikely without access to useful skills. On the other hand, reward-free HRL methods often need to learn far too many skills to achieve proper coverage in high-dimensional domains. In contrast, we introduce the Chain of Interaction Skills (COInS) algorithm, which focuses on controllability in factored domains to identify a small number of task-agnostic skills that still permit a high degree of control. COInS uses learned detectors to identify interactions between state factors and then trains a chain of skills to control each of these factors successively. We evaluate COInS on a robotic pushing task with obstacles—a challenging domain where other RL and HRL methods fall short. We also demonstrate the transferability of skills learned by COInS, using variants of Breakout, a common RL benchmark, and show 2-3x improvement in both sample efficiency and final performance compared to standard RL baselines.