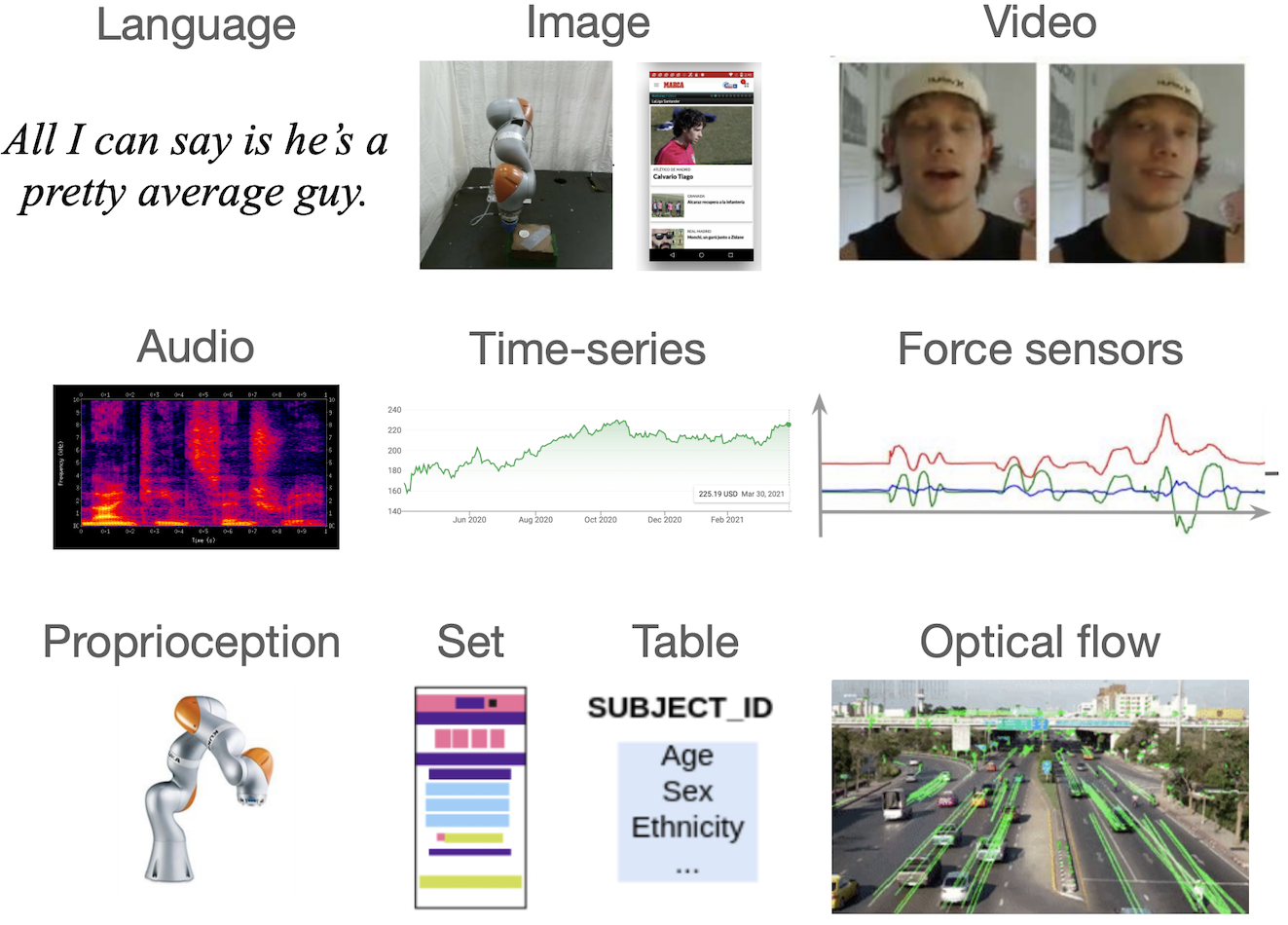
Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. It is a challenging yet crucial area with numerous real-world applications in multimedia, affective computing, robotics, finance, human-computer interaction, and healthcare. Unfortunately, multimodal research has seen limited resources to study (1) generalization across domains and modalities, (2) complexity during training and inference, and (3) robustness to noisy and missing modalities. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiBench, a systematic and unified large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. MultiBench provides an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, MultiBench offers a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench introduces impactful challenges for future research, including scalability to large-scale multimodal datasets and robustness to realistic imperfections. To accompany this benchmark, we also provide a standardized implementation of 20 core approaches in multimodal learning. Simply applying methods proposed in different research areas can improve the state-of-the-art performance on 9/15 datasets. Therefore, MultiBench presents a milestone in unifying disjoint efforts in multimodal research and paves the way towards a better understanding of the capabilities and limitations of multimodal models, all the while ensuring ease of use, accessibility, and reproducibility. MultiBench, our standardized code, and leaderboards are publicly available, will be regularly updated, and welcomes inputs from the community.