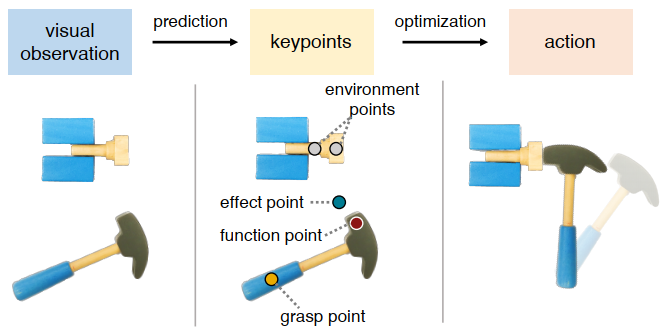
We aim to develop an algorithm for robots to manipulate novel objects as tools for completing different task goals. An efficient and informative representation would facilitate the effectiveness and generalization of such algorithms. For this purpose, we present KETO, a framework of learning keypoint representations of tool-based manipulation. For each task, a set of task-specific keypoints is jointly predicted from 3D point clouds of the tool object by a deep neural network. These keypoints offer a concise and informative description of the object to determine grasps and subsequent manipulation actions. The model is learned from self-supervised robot interactions in the task environment without the need for explicit human annotations.