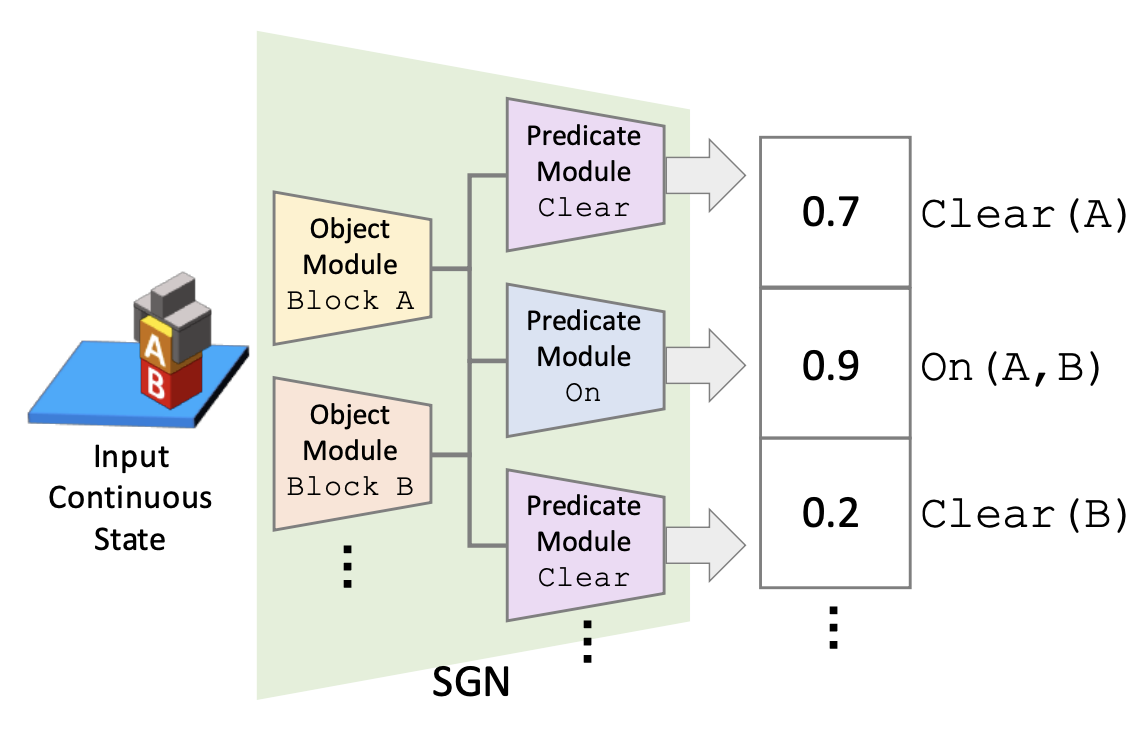
We address one-shot imitation learning, where the goal is to execute a previously unseen task based on a single demonstration. While there has been exciting progress in this direction, most of the approaches still require a few hundred tasks for meta-training, which limits the scalability of the approaches. Our main contribution is to formulate one-shot imitation learning as a symbolic planning problem along with the symbol grounding problem. This formulation disentangles the policy execution from the inter-task generalization and leads to better data efficiency. The key technical challenge is that the symbol grounding is prone to error with limited training data and leads to subsequent symbolic planning failures. We address this challenge by proposing a continuous relaxation of the discrete symbolic planner that directly plans on the probabilistic outputs of the symbol grounding model. Our continuous relaxation of the planner can still leverage the information contained in the probabilistic symbol grounding and significantly improve over the baseline planner for the one-shot imitation learning tasks without using large training data.