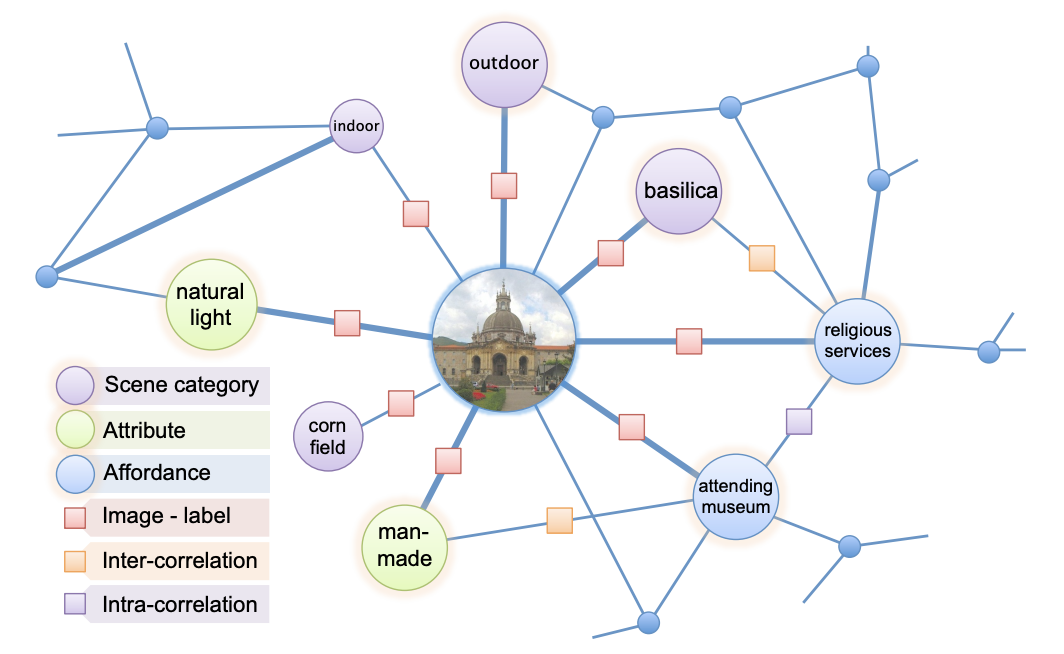
The complexity of the visual world creates significant challenges for comprehensive visual understanding. In spite of recent successes in visual recognition, today’s vision systems would still struggle to deal with visual queries that require a deeper reasoning. We propose a knowledge base (KB) framework to handle an assortment of visual queries, without the need to train new classifiers for new tasks. Building such a large-scale multimodal KB presents a major challenge of scalability. We cast a large-scale MRF into a KB representation, incorporating visual, textual and structured data, as well as their diverse relations. We introduce a scalable knowledge base construction system that is capable of building a KB with half billion variables and millions of parameters in a few hours. Our system achieves competitive results compared to purpose-built models on standard recognition and retrieval tasks, while exhibiting greater flexibility in answering richer visual queries.