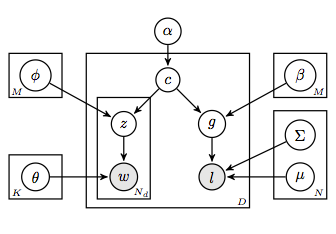
Digital media tend to combine text and images to express richer information, especially on image hosting and online shopping websites. This trend presents a challenge in understanding the contents from different forms of information. Features representing visual information are usually sparse in high dimensional space, which makes the learning process intractable. In order to understand text and its related visual information, we present a new graphical model-based approach to discover more meaningful information in rich media. We extend the standard Latent Dirichlet Allocation (LDA) framework to learn in high dimensional feature spaces.